March 5, 2017
BUILDING NEXUS - A LEGAL MR. ROBOT USING DATA
HopHacks's (Spring '17) 2nd place winning project’s building process documentation. In collaboration with Darren Geng, Hugh Han, and Nikhil Kulkarni.
02/17/16_Friday // HopHacks begins!
20:30 → In-person brainstorming session! Our ideas are focused around identifying hidden trends within public data sets. We thought of using Jon Snow’s data set to identify connections between medical ingredients and diseases. We naively think this could be useful for future predictions of drug effects. We will have to do a lot more research outside of CS to do this project. We also think it would be cool to determine the bias of different news sources towards different people using NLTK.
23:01 → Finally done brainstorming. We settled on an idea to analyze NYT articles for connecting keywords to reveal hidden connections between companies and politicians — sort of like a Mr. Robot. We are calling it Cortex for now. Cortex does not fit into a category for a sponsor prize, but we are not going for a prize — we just want to learn as much as possible this weekend The plan is to retrieve news articles (both past and present) from the New York Times using their API in real time using Apache Spark and Kafka while using NTLK for NLP. Neo4j will be used to construct the full interactive knowledge graph, where nodes represent entities and are connected by individual articles acting as edges. Since, we will have an enormous amount of data, we will use ElasticSearch for quick searching of entities and articles. Python and Flask will be used to build a RESTful API to query ElasticSearch. All this will be presented on a client-side web application using TypeScript and AngularJS 2.0. Oh boy! Hugh and I are on creating the front-end using Angular2. Darren and Nikhil creating the RESTful API using Flask.
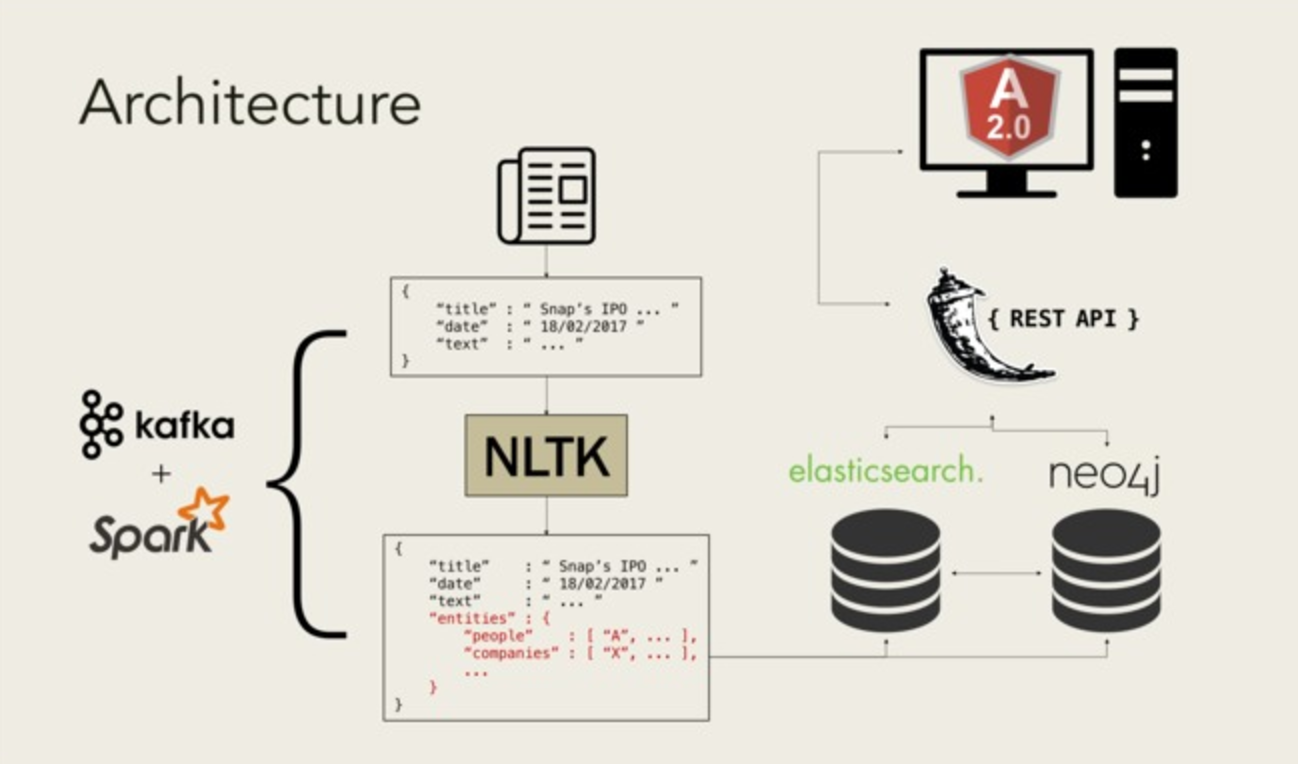
02/18/16_Saturday
01:20 → Hugh and I are having lots of trouble learning Angular2. We want to ultimately read data from the JSON file Darren and Nikhil will format to analyze it based on the user’s query, but we are having trouble with basic functionalities like adding a search bar and interactive calendar. We are jumping from tutorial to tutorial to learn basics. Darren is working on creating the RESTful API using Flask; it is his first time using Flask, so he is reading up on as much documentation as he can while trying to set everything up. Nikhil seems to know the most out of anybody and is catching all of us up to speed. We want to spend the rest of tomorrow (or rather today) working productively, so we decided to get a full night’s sleep tonight and sleep little tomorrow if needed.
11:30 → We managed to successfully get a simple RESTful API to work; it can now handle basic queries from the user. However, we don’t really have any data to work with, so we will finish this part of the project later.
12:00 → Hugh and I were stumped why our web pages were not updated with our code. Then, Darren simply suggested clearing our cache. Oops. Nikhil and Darren are starting to work on creating the rest of the backend. They are starting with retrieving the list of NYT articles and then processing them. Nikhil is teaching Darren, who has experience with Hadoop ecosystems, how everything works since he’s created very similar scripts in the past.
13:30 → We decided to use the code from Angular2’s official tutorial as a framework instead of scraping together our front-end. Hugh and I finally got our calendar to interface with how we expect our, yet-to-be-created, API to behave. We want Darren and Nikhil to deploy the backend so we can with it while using the frontend. However, every wish is cannot be granted — except for wishes for free swag and pizza.
16:00 → Darren and Nikhil ran into a small but fairly annoying bug with the Kafka servers. The scripts they were running weren’t connected properly with the Zookeeper topic needed. They identified the bug (they were listening to the ‘news’ topic rather than the ‘pnews’ topic) and are now done with most of the backend. They are now going to connect it all to ElasticSearch. In the meantime, Nikhil is trying to connect everything with Twitter to see if he can pull the entities’ Twitter profile information as soon as the entities are identified and pulled by StanfordNER.
18:41 → After 1.5 hours of Darren and I trying to understand the code for this framework we decided it would be best to continue using our simple-looking Angular2 tutorial-based web page. We used the Google Maps API to put a map on our webpage that related locations of a particular person.
22:10 → Hugh and I added our search function and Darren and Nikhil deployed the backend.
02/19/16_Sunday
00:03 → We are running into a major bug connecting our backend to our frontend. Hugh and I were using sample data so we didn’t have to wait until Darren and Nikhil were done with the backend to start our work. However, the website absolutely cannot even connect to the backend (doesn’t recognize the server as existing).
01:17 → Turns out, Angular 2.0 has some sort of flag that is set if you wanted to use local data instead of data pulled from a server? With all of us being new to Angular, we had absolutely no idea this flag even existed until we looked into the documentation further and found that this was indeed the case. We removed this flag, and our website is now able to communicate with and recognize our backend. We are now working on implementing full-functionality.
04:19 → We finally integrated our search function to work with our backend! About four hours from the deadline and things are finally working! We renamed Cortex to Nexus. Nexus makes more sense to us since our app acts as a knowledge graph for hidden collections.
05:43 → Cortex can now retrieve a queried person’s Twitter profile to add Twitter images to the articles on our dashboard. We wanted to go for the AWS sponsor award, but we realized we are going to need more than the given $300 for web hosting to host our app on AWS. Big data streaming has the potential to be really expensive and though we think we could easily afford a server to host our entire platform for the next day, we don’t want to risk anything.
06:33 → We are adding more functionality to the website and trying to make it look nicer in these last-seconds (technically last-hours, but with how tired and fried everyone is, every hour might as well be as productive as 10 minutes normally is) touches to the website. In particular, we are trying to extend the Google Maps API functionality some more. Nikhil has, in the meantime, fully connected everything with Neo4j completely, and we now have our entire graph rendered!
08:29 → We submit and most of us take naps. We built a streaming system that can query our database in ElasticSearch that uses NLP and GraphDB in the backend. Hopefully, we wake up for presentations.
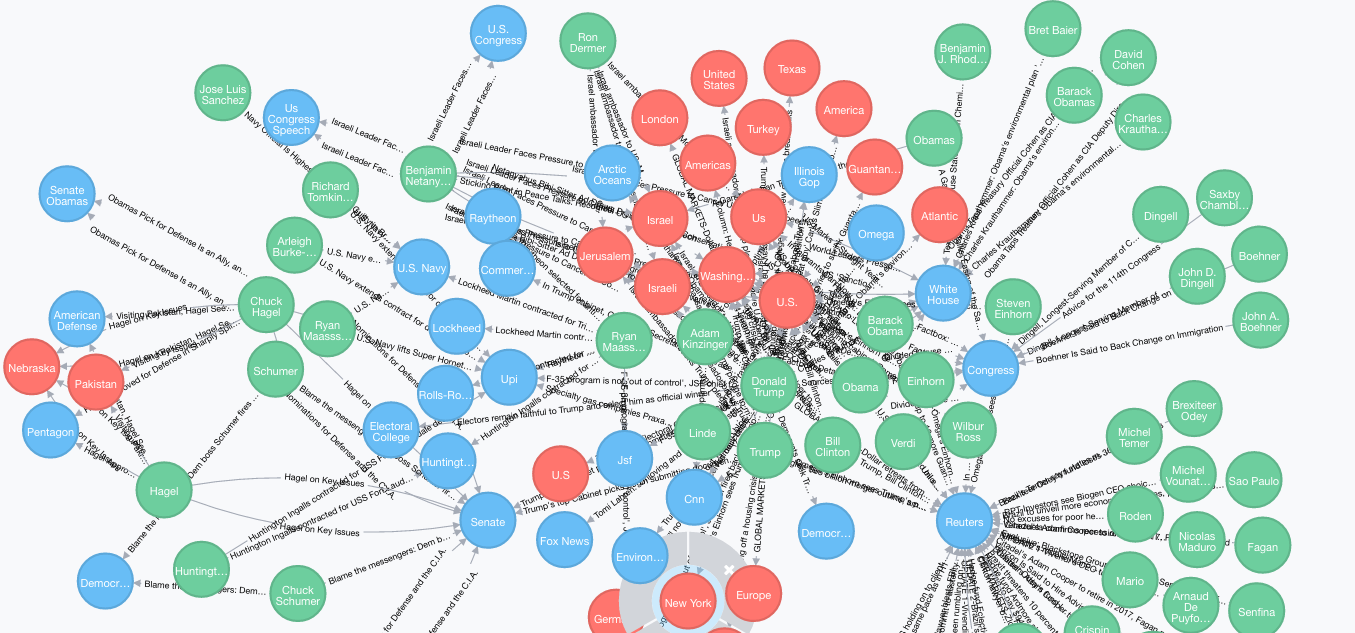
Results
We departed the HopHacks with satisfaction in what we were able to accomplish and ill-feelings towards not learning Angular2 formally. We were pleasantly surprised to receive 2nd place overall in our sleep-deprived states!
Nexus in the news
[ Technical.ly Baltimore] 7 projects that won our attention at HopHacks
